
Open AI Vector Embeddings, Storage and Search
What are vectors, embeddings, how to create them, store them, and perform actions like vector search and more...

What are Vectors
In Natural Language Processing (NLP), text data is often tokenized into words. Each word becomes a separate token making it easier for models and algorithms to analyze and understand textual information.
Once text has been tokenized, each token is represented as a vector in a high-dimensional space. These vector representations are often called embeddings. Word embeddings capture semantic relationships between different words such that words with similar meanings are represented by vectors that are close together in this multi-dimensional vector space.
To transform text into vector you have to pass it through an embedding model often called an encoder. The resulting vectors will contain patterns, relationships and coordinates that help models know their location in a high-dimensional space.
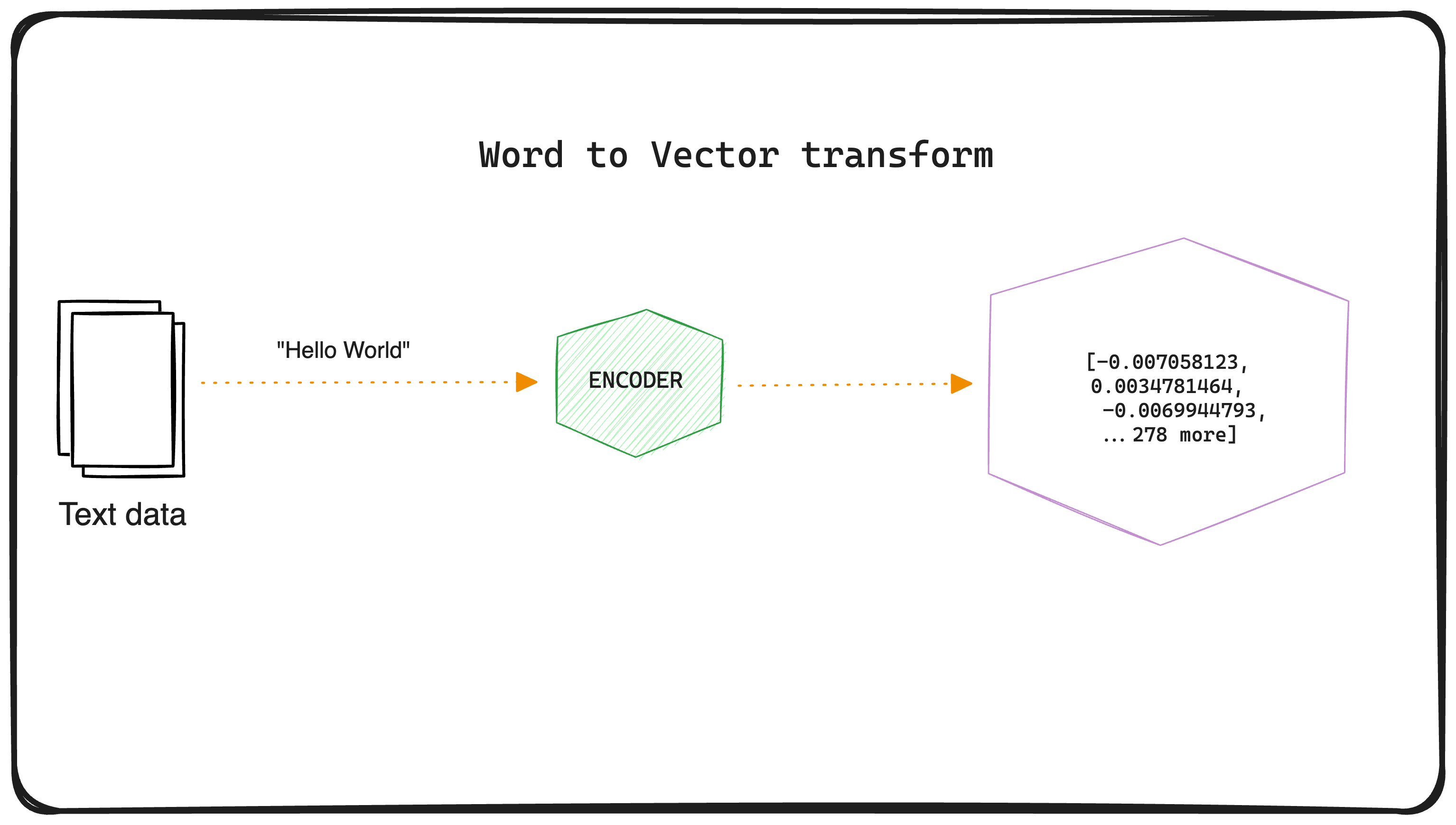
The combination of these vectors act as a multidimensional map we can use to measure the similarity between words. However this is not limited to text, other types of data (images, audio, and videos) can be turned into vectors as well.

Google leverages this functionality (image-to-vector transform) in Chrome to show you results for similar images when you search for it. Once an embedding is created, it can be stored in a vector database from where we can repurpose it to fit different applications and use cases.
Creating vector embeddings
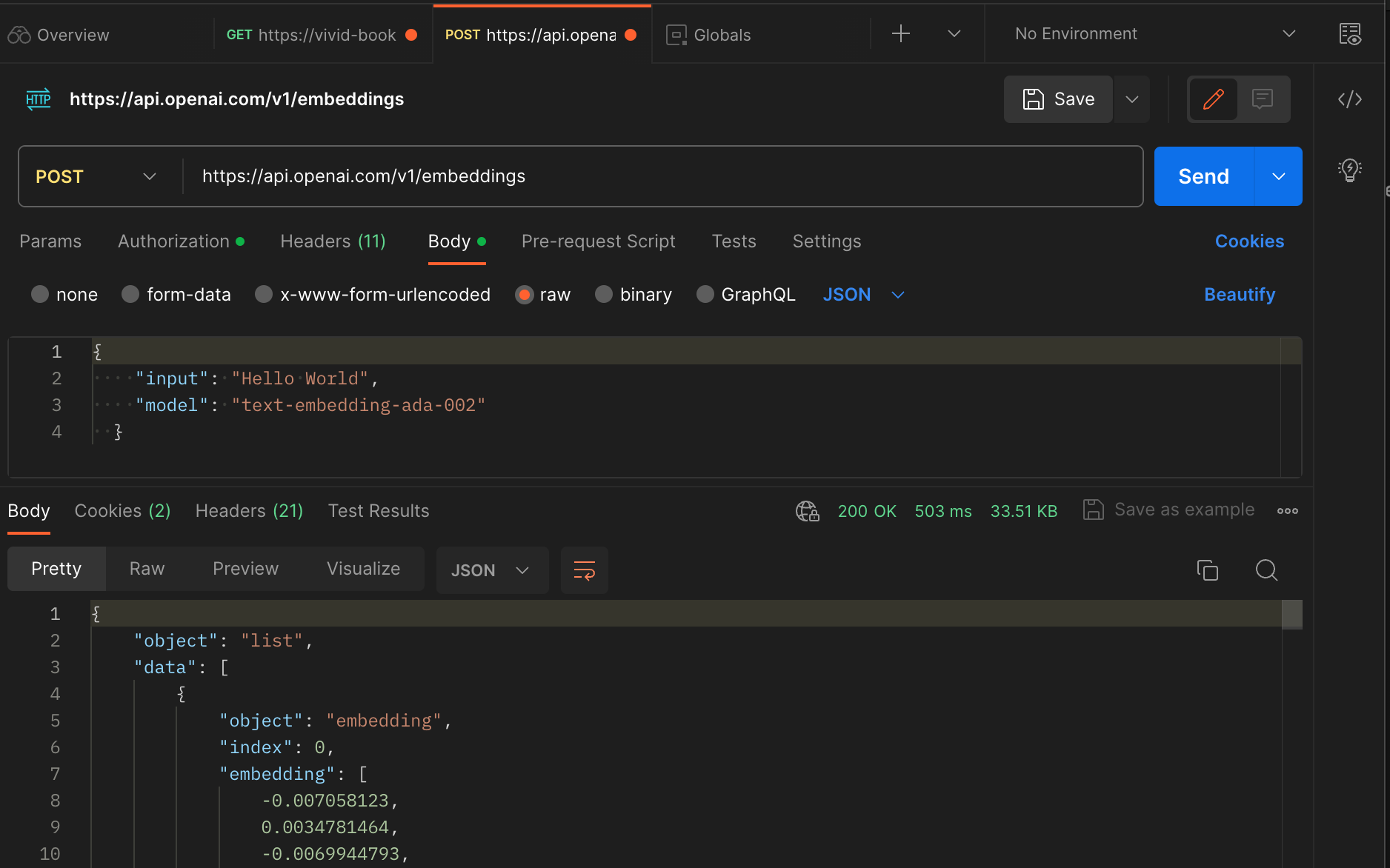
Open AI provides a model that makes it easy for us to create embeddings. What’s more, it is accessible via API. If you don’t have one yet, grab an Open AI API key here and come back to follow along. The API endpoint for creating embeddings with Open AI is https://api.openai.com/v1/embeddings and the request structure is pretty standard. It is documented here if you'd like to learn more.
While i'm focusing on creating embeddings with Open AI in this post, note that there a lot more other approaches you can leverage to creatw embeddings, including Word2Vec, GloVe, FastText, Doc2Vec, BoW etc.
Simply make a POST request to that endpoint, provide an Authorization header and pass your API key as a bearer token. The body of the request should contain:
input- The text you want to transform to embeddings, andmodel- The Open AI encoder model you wish to use for generating the embeddings.
Storing vector embeddings
The race has been on for some time now as database providers have all been working hard to provide this capability through their platforms. Traditional databases store scalar values which makes them unsuitable for storing vectors as they are simply not just primed for it. Hence, the need for a special type of database that is specifically designed to handle this type (vector) of data with performance, scalability and flexibility built-in.
While traditional database providers like MongoDB, Supabase and others have released vector database solutions, other providers like PineCone, Weaviate, Qdrant, Elasticsearch etc exist to support vector storage as well. I haven’t used them all well enough to be opinionated at this point, however, I intend to make recommendations in my next post based on my experiences with these providers as I integrate them into my projects.
With your vectors stored on your vector database of choice, it opens the door for you to implement functionalities like vector search, recommendations, data classifications and so on. Vector search is a really popular use case at the moment so let's talk about it.
Vector Search
Vector search is a Gen AI approach for quickly assessing and approximating the similarity of data based on its vectors. This is why you need vector databases as they are built to natively support functionalities like vector search. Different models apply varying techniques to determine similarities between vectors - Most popular of which is the Approximate Nearest Neighbors (ANN) method. This method often employs the Euclidean distance, Cosine similarity, or other metrics to quantify the similarity between two vectors, but let's not get into that yet.
When performing vector search, the goal is to identify data points in a dataset that are close to the query you’ve provided without having to search through the entire dataset. This is why vector search works great on really large datasets as it finds an approximate, rather than an exact value. Here are some other benefits of vector search that might interest you.
Benefits of vector search
Semantic search - You can search for content without the exact text matches. For example, if you’re searching for a movie on Netflix and you don’t remember the title, you can decide to search for some characters in the movie, or some description of the movie and the relevant results will be returned based on that information.
Scalability - This plays to the point I already touched on that vector search is really great for large datasets because of how they are primed to quickly and efficiently approximate and return the nearest word(s) closest to the provided query.
Flexibility - You can vectorize both structured and unstructured data such that you’re not limited to searching through a particular data type. You can search through images, texts, videos, or audio files.
Conclusion
This post is meant to serve as an entry point into understanding vectors, embeddings, what they are, how to create and store them, and the actions we can perform on them e.g vector search. In a subsequent post I’ll share a hands-on piece where we create a Nextjs application that allows users to POST to a vector database, and also search through that database to find data.



